


- Profile
- たいら・ひろとし 1994年東京大学理学部化学科卒。1996年同大学院理学系研究科修士課程修了。2002年奈良先端科学技術大学院大学情報科学研究科博士後期課程修了。NTTコミュニケーション科学基礎研究所研究主任などを経て、2014年から現職。博士(工学)。福岡県出身。
「東ロボ」プロジェクトで英語を担当
生活の隅々に人工知能(AI=Artificial Intelligence)が入り込むようになり、産業界の発展も人工知能にかかっていると言われています。「人工知能は東大に合格することができるのか」。人工知能の可能性を探ろうと2011年に国立情報学研究所が中心になって始めた「東ロボ」プロジェクトですが、5年目の今年度で一度、充電期間に入ることを決めました。大学入試センター試験模試で毎年順調に成績が向上し、有名大学を含む535の大学で合格率80%以上というレベルに達したものの、「このままでは成績の伸びは頭打ちになり東大合格圏の上位1%は無理」と判断したためです。数学などは好成績でも、英語や国語などで乗り越えられない大きな壁があるからです。プロジェクトでは人工知能の現在の限界が分かっただけでなく、逆に人工知能がかなわない人間の判断力や読解力の凄さを再認識させることにもなりました。人工知能による自然言語処理を研究し、このプロジェクトで英語科目を担当する大阪工大情報メディア学科の平博順准教授に聞きました。
“冬の時代” を越えてAIブーム
実は「東ロボ」プロジェクトが始まる少し前までは人工知能にとって“冬の時代” でした。専門家の意思決定を模倣したエキスパートシステムへの失望や人工知能の研究を推進した国家プロジェクトの「第5世代コンピューター」後の応用展開が少なく、人工知能を搭載したロボットを作るというような研究は下火になり、大量の情報処理などすぐに役立つ研究が中心になっていました。「人工知能を使った…」というフレーズを使うことすらはばかられるほどでした。
それが今のような時代を迎えた契機は、大量のデータからデータのエッセンスを取り出す統計的機械学習技術が進展したことで将棋や囲碁で人間のプロに勝てるようになったこと、人間の脳神経の回路を模したニューラルネットワークがディープラーニング(深層学習)技術によりリバイバルし、人工知能が自律的に入力データの特徴をとらえて学習できるようになり、画像認識などで大幅な性能向上が見られたことです。これによって、大きな話題となり、新たなブームが生まれました。
既存の統計的学習から最新のディープラーニングまで利用
「東ロボ」プロジェクトは、そんな流れを受けて人工知能技術の現時点の可能性を見極めようというのが真の狙いです。「東大入試合格」という誰にでも分かりやすい目標を立てたことで、社会にプロジェクトを認知してもらい、その意義をアピールできました。私が参加したのは大阪工大に着任した2014年からで、前職のNTTコミュニケーション科学基礎研究所の研究員時代からの研究テーマだった自然言語処理の技術を、東ロボくんが苦手とする英語科目の成績向上に生かしてほしいと誘われたのです。
プロジェクトでの私の役割は、平均的な学生にも負けていた大学入試センター試験の英語問題を解くためのプログラムを改良することでした。東ロボくんは問題を入力すると、あらかじめ膨大なデータから基本的には統計的機械学習により学習された解答モデルを使って答えを推測します。英語は大問で6つの分野がありますが、それぞれで解答モデルが違います。
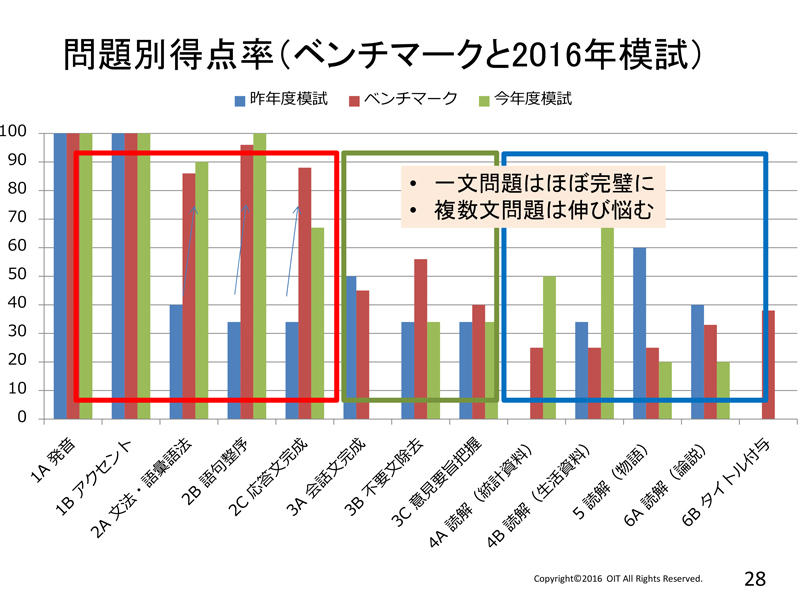
発音・アクセント問題では学習は使用せず、あらかじめ記憶している辞書通りの答えを出すことでほぼ満点が取れています。英文穴埋めの語句整序問題は、大量の英文データから事前に統計学習されたモデルをもとに推測し答えを出します。インターネットのニュース記事などから何十億文という英文データを集め単語の並びを学習しておきます。完全に一致するデータがなくても、東ロボくんは確率的に当てはまる単語を選び出して答えます。この問題は得意分野ですが、当初は6単語の並び方を学習していたものを計算量削減の工夫をして7単語にしたことで正答率が95%にぐんと上がりました。また、既存の機械学習技術だけでなく、最新のディープラーニング技術も取り入れて、東ロボくんが長い文脈をとらえて言葉の予測精度を上げようと試みたことも効果を上げました。
一文の問題はほぼ完ぺきに答えられるようになったのですが、複数文の問題は大きな壁があり伸び悩みました。会話文完成や長文読解の問題などです。ひたすら英語のデータを増やして統計的に答えを導くという方法では根本的にクリアできないものがあるのです。正解を導くために、それが「良い・悪い」「正しい・間違っている」のかといった価値判断が必要になると、東ロボくんは途端に答えられなくなるのです。

会話文完成問題
上記は日本語訳で「君のお父さんが入院したそうですね」「はい、来週手術なんです」「19 僕に何かできることがあったら言ってください」「どうもありがとう」という会話で19に入る文を、①まさにそうです ②問題ありません ③ほっとしました ④それは大変ですね、の4つから選択するという問題です。
日本語訳なら常識的に④が正解だと小学生でも分かりますが、東ロボくんは会話の意味を理解しておらず、統計的に当てはまりそうな文を選び①とか③と答えてしまうのです。常識や価値観に基づく問題が英語や国語には多く、東ロボくんにとっては一番苦手な問題です。この価値判断や意味の読解力が現在の人工知能にはあまりありません。ここを突破する明確な糸口(ブレークスルー)が現時点で見つかっていないことが、プロジェクトで一度充電期間に入る大きな理由です。ここを突破するためには一定期間の基礎研究が必要だと考えています。

価値判断のできるAIを目指し
現在の機械学習技術でも、「良い」「悪い」の情報が付与された大量のデータが与えられれば、「良い」「悪い」を判断する人工知能は作成できます。ウェブ上の動画を大量に人工知能に見せ、その動画とその中身が「良い」「悪い」などの価値の学習をどんどんさせると、ひょっとしたら人間のような判断ができる人工知能が生まれるかもしれません。今それができないのは、人間の基本的な価値判断が「良い・悪い」だけではなく複雑であり、それがどれくらいあるのかもよく分からないからです。人間には本能として刷り込まれている価値判断も膨大にありそうですが、その全体像はまだよく分かっていません。また、その価値判断の答えをデータにして、人手で与えるコストも膨大で現実的ではありません。
こうしたデータを大量に短時間で集める仕組みを編み出せたら、ブレークスルーになるかもしれません。ネット時代にそうした可能性はあります。人間の子供が価値判断を学習する成長過程を、ネットゲームのような形で世界中の利用者から簡単に集められるかもしれません。現在主流の統計的機械翻訳による自動翻訳の精度も昔はなかなか向上しなかったのですが、2000年代に入り急に翻訳精度が上がりました。入力された文例が数百万文規模を超えたことがブレークスルーの一つでした。また将棋や囲碁で人工知能が人間のプロに勝てるようになったのは学習に用いるデータとしてプロの優れた打ち手の大量の電子データを簡単に入手できるようになったのも大きく、データの質も重要です。人工知能の進化にとってデータ収集の質や量が大きなカギなのです。
専門知識では人間をしのぐ
「東ロボ」プロジェクトで改めて分かったことは、人工知能が冬の時代に入り始めた30年前と比べ、人工知能の要素技術は格段に進歩し、世界史や数学など教科を限れば高得点を取れるということでした。将棋や囲碁でプロを負かす人工知能が実現できていることにもつながりますが、専門知識に基づく問題では人工知能が人間をしのいでいる部分もあります。逆に専門知識にならない人間の日常的な知識に基づく問題が非常に大きな壁となっています。
人工知能が自然言語を処理する壁は価値判断の他にも、言葉が実世界の何と対応しているのかを理解させる記号接地問題などさまざまな問題が存在しています。そうした壁を乗り越えられたら、東ロボくんがまた東大入試に挑戦する日が来るかもしれません。
 前の記事へ
前の記事へ








